My Talk at the 1st International Conference on TDD

Search for a command to run...
I'd love to see more articles from you.
Your content is different to the usual stuff (in a good way)!
Thanks for your encouraging words, Catalin!
I think it's always good not to follow the mainstream. That makes us special, right? 😄
I've been less active during a few months, but I am planning to retake writing articles. At the very least, you can expect one more coming in a few days 🙂
Thanks Maxi!
Yours was also great. We had such a great learning experience at the conference. I hope we can repeat next year!
Is Software Engineering really dead in the Artificial Intelligence (AI) era? This question is both provocative and widely debated. It is generating a great deal of discussion on social media and among software developers in general. In this post, I s...

Recently, I published a post on accelerating software engineering with the help of Artificial Intelligence (AI). In that post, I shared my team’s hands-on experience with AI agents, exploring four scenarios where we could easily achieve a significant...

Over the past few months, my team and I have been making extensive use of Artificial Intelligence (AI) – specifically Cursor IDE – in our day-to-day work. It started as a small experiment, but it quickly evolved into a deeper exploration of how Large...

Some people feel uneasy when they test-drive code, so they favor the traditional workflow where testing is an after-development activity. Other people, on the contrary, believe that adding automated tests after development is more challenging, so the...

Most of us are familiar with the problems exhibited by the systems that contain design smells (understanding the term “smell” as defined in Martin Fowler’s book Refactoring: Improving the Design of Existing Code). Some of these problems are: The sys...

Last July 10th, we could witness the first International Conference on Test-Driven Development (TDD).
It was a historic event. The lineup included big names such as GeePaw Hill and one of the original signatories of the Agile Manifesto: James Greening. Kent Beck himself - the (re)inventor of TDD - announced the conference in his Twitter account, which, along with the effort of the organizers, helped reached the non-negligible number of 2000 people registered.
The conference covered a wide range of topics, including a talk about TDD in embedded systems by my friend Francisco Climent, and also a memorable live demo of Test && Commit || Revert (TCR) by organizer Alex Bunardzic.
The event was broadcasted live on YouTube. You can find the full recording here:
I had the honor to talk in this conference.
The title of my talk was:
"On the relationship between units of isolation and test coupling - How to write robust tests with TDD".
I admit that this title reads like an academic paper. This is not necessarily bad, but, if you are not used to this type of writing, the title may not immediately convey to you the message that I want to express.
Hopefully, this post will clear things up for you. Here, I explain the key concepts of my talk: robust tests, test coupling, and units of isolation. In subsequent posts, I will build on this foundation to explain how understanding these concepts will help us write robust tests using TDD.
You can watch my talk here:
It is expected that tests fail when the behavior they verify changes.
This is how tests prevent bugs. We may change the behavior of the system unintentionally, and, when this happens, we want the tests to fail and warn us. Bug prevention is one of the main benefits of automated testing.
But, if behavior does not change and tests fail anyway, then we have tests that fail for no valid reason.
These tests are fragile.
A fragile test is a test that breaks easily. It is a test that fails when it should not fail. It is a test that imposes a heavy burden because we are forced to revisit it often.
Tests should not be fragile; they should be robust.
Robust tests only fail when they should. We can change and improve the structure of the code without altering observable behavior and the tests remain green. This is how tests become a valuable aid, not a burden.
Automated tests should aid refactoring, not impede it.
The main reason why tests become fragile is coupling.
Coupling kills software. This is true for both software applications and test code. Software modules must be loosely coupled to each other. Automated tests must be loosely coupled to the system under test.
To illustrate test coupling, let’s suppose we have a class A that uses two classes B and C. We could reasonably write the following test:

Here, for simplicity, I am loosely speaking about classes B and C as if they were functions, but I think you get the idea.
The design of this test has an important implication: the test knows all the classes (A, B and C). This may be too much knowledge for a test. If we want to edit or remove one of the classes, or add new classes, the test will probably need to be updated. This is high coupling.
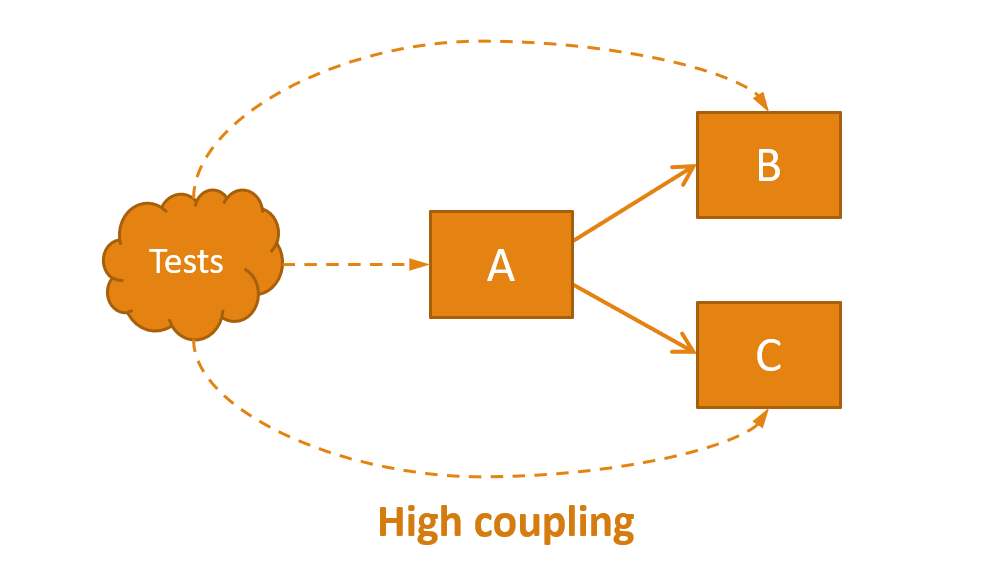
This test smell is sometimes called overspecified software. A test is a specification of behavior, and this test is specifying a lot. It specifies how class A must work internally. It’s specifying the exact algorithm; not what class A should achieve or the results that it should obtain. The test is coupled to the implementation details of A.
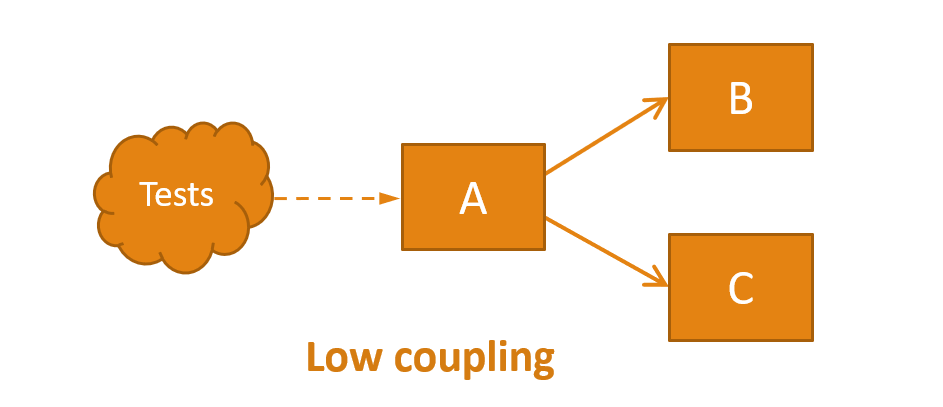
But this type of testing is not the only way to test software. Remember the notion of encapsulation. We could write a test that has a single dependency with A and is unaware of classes B and C. For example, a test can invoke a method in A and assert that the method returns a specific value.
In this case, we can modify B or C, remove any of them or add new classes, and the tests will not need to be updated. This is how tests become robust. This is low coupling.
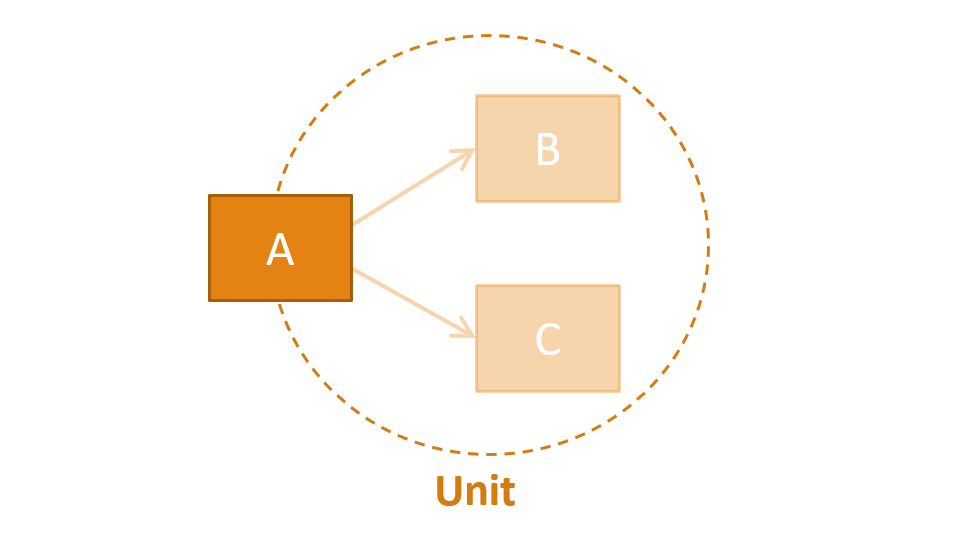
One of the implications of the dependencies that the last picture shows is that classes A, B and C form a unit of isolation: when the tests run, code in A, B and C (and only in these classes) will be executed.
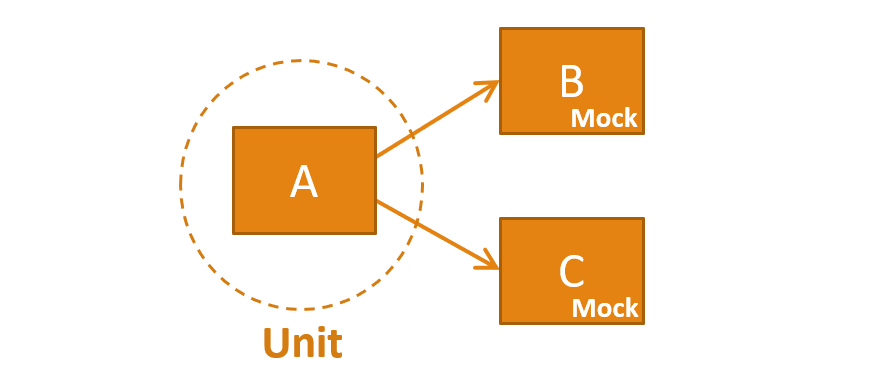
Here, class A acts as an interface or facade for the tests, and classes B and C are implementations details that are internal to the unit. The tests are unaware of these implementation details, and, therefore, the coupling is low.
This contrasts with the first example, where B and C had to be mocks so that the expectations of the test could be set in the arrange step. In this case, only code from A is executed when the tests run, and, therefore, A is the unit of isolation.
Apparently, the notion of unit is important and related to test coupling. In the high-coupling example, the unit is smaller; in the low-coupling example, the unit is bigger.
This reasoning suggests that the bigger the unit, the better, but it is not so easy.
When a test fails and the unit under test is small (e.g., a single method or a single class), it’s more likely that we can identify the cause of the problem easily. However, higher coupling increases fragility, and, consequently, unnecessary rework.
It’s a trade-off between defect localization and maintenance costs.
Unit size impacts test coupling, and, as a consequence, the fragility of the tests. Furthermore, we saw that both small and big units have advantages and disadvantages.
This naturally leads to the question: how can we decide the right size of a unit?
In subsequent posts, I will explore how we can address this question. And I will also show that, if we follow classic TDD, we can obtain robust tests by looking at units of isolation from a slightly different perspective.